История создания,
устройство, строение и применение
графического формата JPEG.
Шелепов
М.И.
Алгоритм JPEG в наибольшей
степени пригоден для сжатия фотографий и картин, содержащих реалистичные сцены
с плавными переходами яркости и цвета. Наибольшее распространение JPEG получил
в цифровой фотографии и для хранения и передачи изображений с использованием
сети Интернет.
С другой стороны, JPEG
малопригоден для сжатия чертежей, текстовой и знаковой графики, где резкий
контраст между соседними пикселями приводит к появлению заметных артефактов.
Такие изображения целесообразно сохранять в форматах без потерь, таких как
TIFF, GIF или PNG.
JPEG (как и другие методы
искажающего сжатия) не подходит для сжатия изображений при многоступенчатой
обработке, так как искажения в изображения будут вноситься каждый раз при
сохранении промежуточных результатов обработки.
JPEG не должен
использоваться и в тех случаях, когда недопустимы даже минимальные потери,
например, при сжатии астрономических или медицинских изображений. В таких
случаях может быть рекомендован предусмотренный стандартом JPEG режим сжатия Lossless JPEG (который, однако, не поддерживается
большинством популярных кодеков) или стандарт сжатия JPEG-LS.
1.
История разработки графического формата JPEG
На сегодняшний день JPEG является одной из ярких
иллюстраций результатов исследований в области развития технологий сжатия
изображений. Аббревиатура JPEG происходит от названия комитета по стандартам Joint Photographic Experts Group (Объединенная
группа экспертов по фотографии), входящего в состав Международной организации
по стандартизации (ISO). В 1987 году две группы исследовавшие методы сжатия цветных и полутоновых данных
ISO и ССIТТ объединили свои группы в комитет. Новый
комитет получил название JPEG. В результате проведенных исследований был
разработан и выпущен новый стандарт
сжатия данных. JPEG. Создатели JPEG
смогли предусмотреть множество коммерческих программ на базе разрабатываемой
технологии, поскольку потребители ожидали маркетинговых предложений по
получению изображений и мультимедиа. Большинство из ранее разработанных методов
сжатия были мало пригодны для сжатия данных полноцветных
многоградационных изображений, содержащих сотни и
тысячи цветов, характеризующих реальный мир. В тот период очень малое число
файловых форматов могли поддерживать растровые изображения с глубиной цвета
24-бит/пиксель и более. Например, формат GIF позволял сохранять только
изображения с максимальной глубиной цвета 8 бит/пиксель, т.е. не более
256 цветов. Его алгоритм сжатия (LZW) мало подходил для сканированных
изображений. Форматы TIFF и BMP позволяли хранить данные глубиной
24-бит/пиксель, но их версии, существовавшие до JPEG, позволяли применять
только схемы кодирования, которые плохо сжимали этот тип данных изображения
(LZW и RLE, соответственно). JPEG явился методом сжатия,
позволяющим сжимать данные полноцветных многоградационных изображений с глубиной от 6 до 24 бит/пиксель
с достаточно высокой скоростью и эффективностью. Сегодня JPEG - эта схема сжатия изображений, которая позволяет
достичь очень высоких коэффициентов сжатия. Правда, максимальное сжатие
графической информации, как правило, связано с определенной потерей информации.
То есть, для достижения высокой степени сжатия алгоритм так изменяет исходные
данные, что получаемое после восстановления изображение будет отличаться от исходного (сжимаемого). Этот метод сжатия используется для работы с полноцветными
изображениями высокого фотографического качества JPEG не был определен в
качестве стандартного формата файлов изображений, однако на его основе были
созданы новые или модифицированы существовавшие файловые форматы.
2. Структура файла, маркеры:
Основы формата JPEG
Для описания структуры файла JPEG я выделил несколько
шагов в преобразовании информации от потока бит в цвета пикселей. Сразу же
определимся, что, например, функция GetByte
возвращает 1 текущий байт из файла (или потока) и перемещает указатель файла к
следующему байту. Функция GetBytes(Count) возвращает указанное число байт и переносит
указатель файла на число прочитанных байт. Прочитав первые два байта из любого файла формата JPEG можно
убедится, что они всегда будут равны FF16 и D816
соответственно. Теперь вернемся к маркерам. Каждый маркер начинается с байта FF16,
вслед за которым идет байт, указывающий на тип маркера. Заметим, что, например,
значение типа FF16 и C016, не является маркером, если
находится в области данных другого маркера, иными словами маркеры,
описывающие структуру файла JPEG не имеют подмаркеров,
следовательно, в данном случае, значение FF16 C016 не
является маркером, хотя и присутствует в файле.
Маркеры
Ниже, в таблице 1 приведены идентификаторы всех
возможных маркеров, встречаемых при декодировании файлов формата JPEG.
|
Тип маркера |
Иденти-фикатор |
Обозначение стандарта |
Определение |
|
SOF0 |
C016 |
Baseline DCT |
Начало
кадра, базовый метод |
|
SOF1 |
C116 |
Extended sequential
DCT |
Начало
кадра, расширенный, последовательный метод |
|
SOF2 |
C216 |
Progressive DCT |
Начало
кадра, прогрессивный метод |
|
SOF3 |
C316 |
Lossless (sequential) |
Начало
кадра, метод сжатия без потерь |
|
SOF5 |
C516 |
Differential sequential
DCT |
Начало
кадра, дифференциальный последовательный метод |
|
SOF6 |
C616 |
Differential progressive
DCT |
Начало
кадра, дифференциальный прогрессивный метод |
|
SOF7 |
C716 |
Differential lossless (sequential) |
Начало
кадра, дифференциальный метод без потерь |
|
JPG |
C816 |
Reserved for JPEG extensions |
Резерв
для последующих расширений формата JPEG |
|
SOF9 |
C916 |
Extended sequential
DCT |
Начало
кадра, расширенный последовательный метод, арифметическое кодирование |
|
SOF10 |
CA16 |
Progressive DCT |
Начало
кадра, прогрессивный метод, арифметическое кодирование |
|
SOF11 |
CB16 |
Lossless (sequential) |
Начало
кадра, метод без потерь, арифметическое кодирование |
|
SOF13 |
CD16 |
Differential sequential
DCT |
Начало
кадра, дифференциальный последовательный метод, арифметическое кодирование |
|
SOF14 |
CE16 |
Differential progressive
DCT |
Начало
кадра, дифференциальный прогрессивный метод, арифметическое кодирование |
|
SOF15 |
CF16 |
Differential lossless (sequential) |
Начало
кадра, дифференциальный метод без потерь, арифметическое кодирование |
|
DAC |
CC16 |
Define arithmetic coding
conditioning(s) |
Определений
условий арифметического кодирования |
|
DHT |
C416 |
Define Huffman table(s) |
Определение
таблиц Хаффмана |
|
RST0…RST7 |
D016...D716 |
Restart marker number 0…7 |
Определение
интервала перезапуска от 0 до 7 |
|
SOI |
D816 |
Start of image |
Начало
изображения |
|
EOI |
D916 |
End of image |
Конец
изображения |
|
SOS |
DA16 |
Start of scan |
Начало
скана |
|
DQT |
DB16 |
Define quantization
table(s) |
Определение
таблиц квантования |
|
DNL |
DC16 |
Define number of lines |
Определение
числа линий |
|
DRI |
DD16 |
Define restart interval |
Определение
интервала перезапуска |
|
DHP |
DE16 |
Define hierarchical
progression |
Определение иерархической прогрессии |
|
EXP |
DF16 |
Expand reference component(s) |
Раскрытие
справочных компонент |
|
COM |
FE16 |
Comment |
Комментарий |
|
APP0…APP15 |
E016...EF16 |
Reserved for application segments |
Зарезервированная
информация о приложениях упаковщиках |
|
JPG0…JPG13 |
F016...FD16 |
Reserved for JPEG extensions |
Резерв
для последующих расширений формата JPEG |
|
TEM |
0116 |
For temporary private use in
arithmetic coding |
Для
временного локального определения настроек арифметического кодирования |
|
RES |
0216...BF16 |
Reserved |
Резерв
для последующих расширений формата JPEG |
Таблица
1. Маркеры формата JPEG
В приведенной таблице 1 зеленым цветом выделены
те маркеры, которые практически всегда встречаются в любом файле формата JPEG и
требуют обязательной обработки. Желтым цветом обозначены так же часто
встречающиеся маркеры, но которые не требуют обязательной обработки для
получения изображения. Остальные маркеры в 90% случаев не встречаются в файлах
JPEG и не требуют никакой обработки.
Структура типичного маркера:
![]()
Рисунок 3. Структура маркера
Идентификатор – два байта,
которые указывают на тип маркера.
Длинна
– два байта, которые содержат длину данных маркера в байтах (Обратный
порядок) и собственную длину. То есть если данные маркера имеют длину 10
байт, то значение длинны будет равно 10 (длинна данных маркера) + 2 (два байта
со значением длинны) = 12.
Данные маркера – набор байт, требующих обработки в соответствии с типом маркера.
Внимание!
Маркеры TEM, RST0…RST7, SOI, EOI не имеют
длинны и данных маркера и, следовательно, состоят из двух байт.
Все двухбайтовые величины в файлах формата JPEG имеют
обратный порядок.
Стандарт JPEG достаточно гибок в том, что касается
расположения маркеров внутри файла. Его строжайшее правило предписывает, чтобы
файл начинался с маркера SOI и заканчивался маркером EOI. В большинстве
остальных случаев маркеры могут появляться в любом порядке.
Основное требование заключается в том, что если данные
из одного маркера нужны для обработки второго маркера, первый маркер должен
располагаться до второго.
Сжатые данные компонентов являются единственной частью
файла JPEG, которые не встречаются внутри маркера. Сжатые данные всегда следуют
сразу после маркера SOS. Поскольку в нем нет информации о
длине, необходимо просканировать данные до следующего маркера (отличного от RST
Сжатые данные компонентов являются единственной частью файла JPEG, которые не
встречаются внутри маркера. Сжатые данные всегда следуют сразу после
маркера SOS. Поскольку в нем нет информации о длине, необходимо просканировать
данные до следующего маркера (отличного от RSTN), чтобы найти конец сжатых
данных без их восстановления. Маркеры RSTN являются единственными
маркерами, которые встречаются внутри сжатых данных, и они не встречаются в
маркерах.
Метод JPEG-сжатия разработан так, что он редко создает
в сжатых данных значение FF16. Когда требуется присутствие такого
значения в сжатых данных, оно кодируется как последовательность 2-х байтов, в
которой за FF16 следует 0016. Это облегчает программам
сканирование файлов JPEG с целью поиска конкретных маркеров.
В примере, идущем вместе с этим проектом использован
алгоритм чтения маркеров из файла JPEG, который сначала читает идентификатор, а
за тем, при необходимости, загружает данные маркера в память. В упрощенном виде
данный алгоритм изображен на врезке ниже.
procedure ReadMarker;
begin
MarkerName:=GetByte;if MarkerName<>$FF then Error;
MarkerName:=GetByte; MarkerSize:=0;if (MakrerName<>SOI) and (MarkerName<>EOI) then
begin
MarkerSize:=Swap(GetBytes(2))-2; MarkerData:=GetBytes(MarkerSize);end;
end;
После выполнения описанной выше процедуры поле MarkerName будет содержать идентификатор текущего маркера,
поле MarkerSize – Размер данных маркера, а поле MarkerData – данные маркера. Если поле MarkeSize=0, то об
этом свидетельствует то, что встретившийся маркер был маркером начала или конца
изображения и следует проверить не является ли текущий
маркер, маркером начала или конца изображения. Если является, то читаем
следующий маркер, если нет то сообщаем об ошибке, т.к.
уже достигнут конец файла с изображением или сам файл поврежден.
В описания формата файла JPEG всегда будут действовать
три правила, которые, в дальнейшем, повторятся в работе не
будут:
1.
В
сжатых данных могут появляться только маркеры RST и DNL.
2.
Изображение
должно начинаться с маркера SOI.
3.
Последним
маркером в файле должен быть маркер EOI, и он должен следовать сразу после
сжатых данных из последнего скана изображения.
Маркеры АРРN
Маркеры АРР0…APP15
содержат специфические данные программы. Эти маркеры используются программами
редактирования изображений для сохранения дополнительной информации, помимо
той, что задается стандартом JPEG. Формат этих маркеров зависит от конкретной
программы. Поле длины, располагающейся после маркера, может использоваться для
пропуска данных маркера. За исключением маркеров АРР0,
используемых форматом JFIF, программа может игнорировать маркеры АРР, которые
она не распознает. Если программе необходимо сохранить информацию, выходящую за
пределы возможностей форматов JPEG и JFIF, то для сохранения этой информации
программа может создать маркеры АРРN.
Внутри файла JPEG маркеры АРРN могут появляться где
угодно. По соглашению; программы, которые создают маркеры АРРN,
сохраняют свое имя (заканчивающееся нулем) в начале маркера, с целью
предотвращения конфликтов с другими программами. Программа, обрабатывающая
маркеры АРРN должна проверять не только
идентификатор маркера, но также имя программы, записавшей маркер.
Маркеры СОМ
Маркер COM (Comment -
Комментарий) используется для хранения строк комментариев, например, информации
об авторских правах. Их интерпретация зависит от конкретной программы, однако
JPEG-кодер должен предполагать, что декодер будет игнорировать эту информацию.
Именно маркер СОМ, а не маркер АРРN должен
использоваться для хранения простого текста комментария. В файле JPEG он может
появляться где угодно.
Маркеры DHT
Маркер DHT (Define Huffman Table – Определение
таблицы Хаффмана) определяет (или переопределяет) таблицы Хаффмана, которые
идентифицируются типом (АС или DC) и числом. Один маркер DHT может определять
множество таблиц, однако базовый режим ограничен двумя таблицами каждого типа,
а прогрессивный и последовательный режимы ограничены четырьмя таблицами.
Единственное ограничение на размещение маркеров DHT состоит в том, что если
скан требует наличия особого идентификатора таблицы или типа, идентификатор
должен быть определен ранее в файле маркером DHT.
Структура маркера DHT показана в Таблице 2. Каждая
таблица Хаффмана представляет собой 17 байтов фиксированных данных, за которыми
следует поле переменной длины, включающее до 256 дополнительных байтов. Первый
фиксированный байт содержит идентификатор таблицы. Следующие 16 байтов образуют
массив из 1-байтовых целых чисел без знака, элементы которого задают число
кодов Хаффмана для каждой возможной длины кода (1—16). Сумма из 16 длин кодов
представляет собой число значений в таблице Хаффмана. Каждое значение равно 1
байту и за ним следуют, согласно порядку кода Хаффмана, счетчики длины (length counts). Подробнее
структура таблиц Хаффмана описывается
|
Размер поля |
Описание |
|
1
байт |
4
старших бита определяют тип таблицы. Значение 0 указывает на таблицу DC,
значение 1 указывает на таблицу АС. 4 младших бита определяют идентификатор
таблицы. Значение этого идентификатора равно 0 или 1, для кадров базового
метода и 0, 1, 2 или 3 для кадров прогрессивного и расширенного методов. |
|
16
байт |
Счетчик
кодов Хаффмана длиной от 1 до 16. Каждый счетчик хранится в 1 байте. |
|
Переменный |
1-байтовые
символы, сортированные по коду Хаффмана. Число символов равно сумме 16
счетчиков кода. |
Таблица
2. Формат таблицы
Хаффмана.
Число таблиц Хаффмана, указываемое маркером DHT,
определяется из поля длины. Программа должна поддерживать ведение счетчика,
который инициализируется значением длины поля минус 2. Каждый раз, когда
считывается таблица, из счетчика вычитается длина этой таблицы. Когда значение
счетчика достигнет нуля, все таблицы будут прочитаны. В маркере DHT не
допускается наличие заполнителей, поэтому если значение счетчика становится
отрицательным, то это служит указателем недостоверности файла.
Маркеры DRI
Маркер DRI (Define Restart Interval – Определение
интервала перезапуска) задает число MCU’s между
маркерами перезапуска (restart markers)
внутри сжатых данных. Значение поля длиной 2 байта, следующего за маркером,
всегда равно 4. В маркере есть только одно поле данных - 2-байтовое значение,
которое определяет интервал перезапуска (restart interval). Если интервал равен нулю, это означает, что
маркеры перезапуска не используются. Маркер DRI с ненулевым значением интервала
перезапуска может применяться для повторной активизации маркеров перезапуска
далее в изображении.
Маркеры DRI могут появляться в любом месте файла для
определения или переопределения интервала перезапуска, который сохраняет свое
действие до конца изображения или пока другой маркер DRI не изменит его. Чтобы
маркеры перезапуска были включены в сегмент сжатых данных, в файле должен
присутствовать где-нибудь маркер DRI.
Маркеры перезапуска помогают в нейтрализации ошибок. Если декодер находит
искаженные данные скана, он может использовать идентификатор маркера
перезапуска и интервал перезапуска для определения места, с которого будет
возобновлено декодирование изображения. Число пропускаемых
MCU”s можно определить с помощью следующей формулы:
Число пропускаемых MCU’s = Интервал перезапуска × ((8 + Идентификатор
текущего маркера - Идентификатор последнего маркера) mod
8)
Пример: Предположим, что интервал перезапуска равен
10. После того, как были декодированы 80 MCU’s, из
входного потока считывается маркер RST7. Если декодер встречает
искаженные данные до того, как приступит к чтению следующего маркера
перезапуска (RST0), он прекращает декодирование и сканирует входной
поток в поисках следующего маркера перезапуска. Если следующим маркером
является RST3, декодер пропускает 40 MCUs
(= 10 × ((8 + 3 - 7) mod 8)), начиная с
последней известной точки (80), Декодер возобновляет декодирование со 121-го
MCU в изображении.
Маркеры DQT
Маркер DQT (Define Quantization Table – Определение
таблиц квантования) определяет (или переопределяет) таблицы квантования,
используемые в изображении. Маркер DQT может определять несколько таблиц
квантования (до 4). Определение таблиц квантования следует за полем длины
маркера. Значение поля длины равно сумме размеров таблиц плюс 2 (для учета поля
длины).
Формат определения таблиц квантования показан в Таблице
3. Каждая таблица начинается с 1-го байта, который содержит информацию о
таблице. Если 4 старших бита информационного байта равны нулю, каждое значение
таблицы квантования равно 1 байту, а длина всего определения таблицы составляет
65 байтов. Если значение 4 старших битов равно 1, размер каждого значения
таблицы квантования равен 2 байтам и длина определения таблицы составляет 129
байтов. Двухбайтовые значения квантования могут использоваться только с 12-битовыми
дискретизованными данными.
|
Размер поля |
Описание |
|
1
байт |
4
младших бита являются идентификатором таблиц квантования таблицы (0, 1, 2 или
3). 4 старших бита задают размер значения квантования (0 – однобайтовые
величины, 1– двухбайтовые величины). |
|
64
или 128 байт |
64
однобайтовых или двухбайтовых значений таблицы квантования без знака. |
Таблица
3. Формат таблицы
квантования.
4 младших бита определяют числовой идентификатор
таблицы, который может быть равен 0, 1, 2 или 3. За информационным байтом
следуют 64 значения квантования, которые хранятся в JPEG в зигзагообразном
порядке.
В файле изображения маркеры DQT могут появляться где
угодно. Единственное ограничение состоит в том, что если скану требуется
таблица дискретизации, она должна быть определена в предшествующем маркере DQT.
Маркеры EOI
Маркер EOI (End of Image – Конец изображения)
отмечает конец JPEG-изображения и должен находиться в конце JPEG-файла. В файле
допускается присутствие только одного маркера EOI, за которым не может
располагаться ни один из прочих маркеров. Маркер EOI стоит в одиночку.
Маркеры RSTN
Маркеры перезапуска RST0…RST7
используются для маркировки блоков независимо кодированных сжатых данных скана.
В этих маркерах отсутствуют поле длины и данные, а сами маркеры могут
встречаться только внутри сжатых данных скана.
Маркеры перезапуска могут использоваться для
нейтрализации ошибок. Интервал между маркерами перезапуска определяется
маркером DRI (Define Restart
Interval – Определение интервала перезапуска). Таким
образом, если интервал перезапуска равен нулю, то маркеры перезапуска не
используются. В сканах маркеры перезапуска встречаются в последовательности RST0,
RST1,...RST7, RST0...
Маркеры SOI
Маркер SOI (Start of Image – Начало изображения)
отмечает начало JPEG-изображения. Он может находиться в самом начале файла и во
всем файле может быть только один такой маркер. Маркер SOI стоит в одиночку.
Маркеры SOFN
Маркер SOFN (Start
of Frame – Начало кадра)
определяет кадр. Хотя существует множество типов кадров, у всех у них
одинаковые форматы. Маркер SOF состоит из фиксированного заголовка следующего
после поля длины маркера. Далее располагается список структур, которые
определяют каждый компонент, используемый в кадре. Структура фиксированного
заголовка показана в Таблице 4, а структура компонента приводится в Таблице
5.
|
Размер поля |
Описание |
|
1
байт |
Счетчик
компонентов |
|
2
байта счетчика компонентов |
Дескрипторы
компонентов скана (см. Таблицу 7) |
|
1
байт |
Начало
спектрального выделения (0 – 63) |
|
1
байт |
Конец
спектрального выделения (0 – 63) |
|
1
байт |
Последовательное
приближение (два 4-битовых поля, каждое со значением в диапазоне 0 – 13) |
Таблица
6. Структура маркера
SOS.
|
Размер поля |
Описание |
|
1
байт |
Идентификатор
компонента |
|
1
байт |
4
старших бита задают таблицу Хаффмана DC, а 4 младших бита задают таблицу
Хаффмана АС |
Таблица
7. Описание дескриптора
в маркере SOS.
Дескрипторы компонентов располагаются в той же
последовательности, в которой компоненты располагаются в MCU’s
данных скана. Хотя не все компоненты из маркера SOFN могут быть в
наличии, порядок компонентов в маркере SOS должен совпадать с порядком
компонентов в маркере SOFN. Идентификатор компонента в дескрипторе
скана должен соответствовать значению идентификатора компонента, определяемому
в маркере SOFN. Идентификаторы таблиц Хаффмана АС и DC должны совпадать с
идентификаторами таблиц Хаффмана, определяемыми в предшествующем маркере DHT.
Стандарт JPEG допускает присутствие в скане от 1 до 4
компонентов, но существует ряд других ограничений, накладываемых на число
компонентов. Формат JFIF ограничивает изображение тремя компонентами. В
прогрессивных сканах может присутствовать только 1 компонент, если начало
спектрального выделения отлично от нуля. Стандарт JPEG также устанавливает для
количества единиц данных, которое может быть в MCU, достаточно низкий предел
равный 10, что может ограничивать число компонентов в скане.
В последовательном скане начало спектрального
выделения должно быть равно нулю, конец спектрального выделения – 63, а
последовательное приближение – нулю. Если в прогрессивном скане начало
спектрального выделения равно нулю, то конец спектрального выделения тоже
должен быть равен нулю. В остальных случаях значение конца спектрального
выделения должно быть не меньше, чем значение начала спектрального выделения.
В файле маркер SOS должен появляться после маркера SOFN. Ему должны предшествовать маркеры DHT, которые определяют все таблицы Хаффмана, используемые в скане, и маркеры DQT, которые определяют все таблицы квантования, используемые компонентами скана.
3. АЛГОРИТМ ОБРАБОТКИ ДАННЫХ JPEG
Спецификация JPEG определяет минимальные требования
стандарта, которые должны поддерживаться всеми программами, использующими этот
метод. JPEG основан на схеме кодирования, базирующейся
на дискретных косинус-преобразованиях (DCT). DCT —
это общее имя определенного класса операций, данные о которых были опубликованы
несколько лет назад. Алгоритмы, базирующиеся на DCT, стали основой различных
методов сжатия. Эти алгоритмы сжатия базируются не на поиске одинаковых
атрибутов пикселей (как в RLE и LZW), а на разнице
между ними.
В силу своей природы они всегда кодируют с потерями,
но способны обеспечить высокую степень сжатия при минимальных потерях данных.
Схема JPEG эффективна только при сжатии многоградационных
изображений, в которых различия между соседними пикселями, как правило, весьма
незначительны. Практически JPEG хорошо работает только с изображениями,
имеющими глубину хотя бы 4 или 5 битов/пиксель на цветовой канал. Основы
стандарта определяют глубину входного образца в 8 бит/пиксель. Данные с меньшей
битовой глубиной могут быть обработаны посредством масштабирования до 8
бит/пиксель, но результат для исходных данных с низкой глубиной цвета
может быть неудовлетворительным, поскольку между атрибутами соседних пикселей
будут существенные различия. По подобным причинам плохо обрабатываются исходные
данные на основе цветовых таблиц, особенно если изображение представляется в
размытом виде.
Процесс сжатия по схеме JPEG включает ряд этапов (рис.
1):
- Преобразование изображения в оптимальное цветовое
пространство.
-Субдискретизация
компонентов цветности усреднением групп пикселей.
-Применение дискретных косинус-преобразований
для уменьшения избыточности данных изображения.
-Квантование каждого блока коэффициентов DCT с
применением весовых функций, оптимизированных с учетом визуального восприятия
человеком.
- Кодирование результирующих коэффициентов (данных
изображения) с применением алгоритма Хаффмена для
удаления избыточности информации.
Рассмотрим вкратце особенности каждого из
перечисленных этапов. При этом хотелось
бы обратить внимание на то, что декодирование JPEG осуществляется в обратном
порядке.
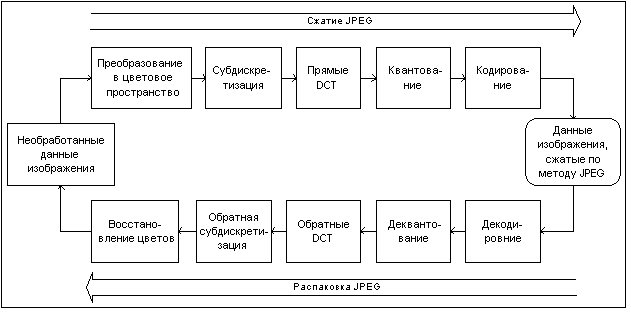
Рис. 1 Структура JPEG - преобразований
Цветовое
пространство
В принципе алгоритм
JPEG способен кодировать изображения, основанные на любом типе цветового
пространства. JPEG кодирует каждый компонент цветовой модели отдельно, что
обеспечивает его полную независимость от любой модели цветового пространства
(например, от RGB, HSI или CMYК).
В случае применения
цветового пространства яркость/цветность, например такого, как YUV или YCbCr, достигается лучшая степень сжатия. Компонента Y
представляет собой интенсивность, а U и V - цветность. Эта модель может быть
переведена в RGB посредством преобразования без какой-либо коррекции
насыщенности. Для полутоновых изображений (в градациях серого)
используется только одна составляющая Y.
Преобразование
цветовой модели RGB в модель Y Cb Cr
осуществляется с помощью следующих соотношений:
Y = 0,299 R +
Cb = - 0,1687 R -
Cr = 0,5 R -
Обратное преобразование
модели Y Cb Cr в модель RGB
осуществляется с помощью подобных соотношений:
R = Y + 1,402 (Cr-128);
G = Y - 0,34414 (Cb-128) - 0,71414 (Cr-128);
B = Y + 1,772 (Cb-128).
Субдискретизация компонентов цветности
На экране компьютера мы практически никогда не видим
реально полноцветных изображений реального мира. Это
объясняется ограниченными возможностями по цифровому представлению в памяти
ПЭВМ, искажениями при воспроизведении цвета монитором и видеокартой. В
результате на мониторе ПЭВМ воспроизводятся, в зависимости от выбранного
видеорежима, цвета наиболее близкие к реальным.
Большая часть визуальной информации, к которой
наиболее чувствительны глаза человека, состоит из высокочастотных, полутоновых
компонентов яркости (Y) цветового пространства YCbCr.
Две других составляющих цветности (Сb и Сr) содержат высокочастотную
цветовую информацию, к которой глаз человека менее чувствителен. Следовательно,
определенная ее часть может быть отброшена и, тем самым, можно уменьшить
количество учитываемых пикселей для каналов цветности. Например, в изображении
размером 1000x1000 пикселей можно использовать яркости всех 1000x1000 пикселей,
но только 500х500 пикселей для каждого компонента цветности. При таком
представлении каждый пиксел цветности будет
охватывать ту же область, что и блок 2х2 пиксела (для
яркости). В результате мы сохраним для каждого блока 2х2 всего 6 пиксельных
значений (4 значения яркости и по 1 значению для каждого из двух каналов
цветности) вместо того, чтобы использовать 12 значений при обычном описании.
Практика показала, что уменьшение объема данных на 50% почти незаметно
отражается на качестве большинства изображений.
Однако в случае общепринятых цветовых моделей типа RGB
такое представление данных невозможно, поскольку каждый цветовой канал RGB
несет некоторую информацию яркости и любая потеря разрешения весьма заметна.
Уменьшение разрешения каналов цветности путем субдискретизации, или усреднения групп пикселей
осуществляется компрессором JPEG.
Стандарт JPEG предлагает несколько различных вариантов
определения коэффициентов дискретизации, или относительных размеров каналов субдискретизации. Канал яркости всегда остается с полным
разрешением (дискретизация 1:1). Для обоих каналов цветности обычно
производится субдискретизация 2 - в горизонтальном
направлении и 1:1 или 2:1 — в вертикальном. При этом
подразумевается, что цветности пикселов будет
охватывать ту же область, что и блок 2х1 или 2х2 яркости пикселей. Согласно
терминологии JPEG, эти процессы называются 2h1v - и 2h2v - дискретизацией
соответственно.
Другой общепринятой спецификацией дискретизации 2hlv
является 4:2:2, а дискретизации 2h2v — 4:2:0; последняя спецификация связана с
телевидением. Дискретизация 2hlv используется достаточно широко, поскольку
соответствует стандарту NTSC (Национальный комитет по телевизионным стандартам
США), однако при весьма незначительном выигрыше в качестве она обеспечивает
меньшую степень сжатия, чем дискретизация 2h2v.
Цветовые модели RGB, HSI и CMY используют в полезной
визуальной информации все три цветовых компонента. Это затрудняет ее выборочное
отбрасывание, а, следовательно, и уменьшает степень сжатия данных. Полутоновые
изображения не имеют цветового пространства и, следовательно, не нуждаются в
преобразовании.
Поскольку средства визуализации и представления
информации являются цифровыми, в них изначально заложена определенная система
квантования сигнала. В конечном итоге, уровень квантования определяется
глубиной цвета, т. е. количеством кодовых комбинаций, которые используются для
кодирования цвета. Этот процесс и называется квантованием цвета.
Поскольку в квантованной матрице отсутствует
значительная доля высокочастотной информации, имеющейся в исходной матрице,
первая часто сжимается до половины своего первоначального размера или даже еще
больше. Реальные фотографические изображения часто совсем невозможно сжать с
помощью методов сжатия без потерь, поэтому 50%-ное сжатие признается достаточно
хорошим.
После конвертации
графических данных в цветовое пространство типа LAB, отбрасывается часть
информации о цвете (в зависимости от конкретной реализации алгоритма).
Первоначально в спецификациях формата не была
предусмотрена субтрактивная цветовая модель CMYK.
Фирма Adobe ввела поддержку функции цветоделения.
Однако использование цветовой модели CMYK в JPEG для многих программ
проблематично. Более надежным решением считается использование JPEG-сжатия в
EPS-файлах (Photoshop).
3.1
Сегментация изображения
Сегментация
изображения применяется с целью деления его на два и более
сегментов (подизображений). Это облегчает
буферизацию данных изображения в памяти ПЭВМ, ускоряет их произвольную выборку
с диска, и позволяет хранить изображения размером свыше 64х64 Кб. JPEG
поддерживает три типа Сегментации изображений: простую, пирамидальную и
комбинированную.
При простой
сегментации изображение делится на два или более сегментов фиксированного
размера. Все простые сегменты кодируются слева направо и сверху вниз, являются
смежными и неперекрывающимися. Сегменты должны иметь
одинаковое количество выборок и идентификаторов компонентов, и быть
закодированными по одной схеме. Сегменты в нижней и правой частях
изображения могут быть меньшего размера, чем "внутренние" сегменты,
поскольку величина изображения не обязательно должна быть кратной размерам
сегмента.
При пирамидальной сегментация изображение также
делится на сегменты, а каждый из них, в свою очередь, — на еще более мелкие
сегменты . При этом используются различные уровни
разрешения. Моделью такого процесса является сегментированная пирамида
изображения JPEG (JPEG Tiled
Image Pyramid, JTIP), отражающая процедуру создания пирамидального
JPEG-изображения с несколькими уровнями разрешения.
В схеме JTIP
последовательные слои одного изображения хранятся с разным разрешением. Первое
изображение, записываемое на вершине пирамиды, занимает одну шестнадцатую часть
установленного размера экрана и называется виньеткой. Применяется оно
для быстрого воспроизведения содержимого изображения. Это приобретает особую
значимость при работе с программами просмотра (браузерами). Следующее
изображение занимает одну четвертую часть экрана и называется мажеткой. Обычно она используется в тех случаях,
когда на экране необходимо одновременно отобразить два и более изображений.
Далее следуют полноэкранное изображение с низким разрешением, изображения с
последовательно повышающимся разрешением и, наконец, оригинал изображения.
При пирамидальной сегментация целесообразен процесс
внутренней сегментации, когда каждый сегмент кодируется как часть одного потока
JPEG-данных. Иногда может применяться процесс внешней сегментации, при котором
каждый сегмент представляет собой отдельно кодируемый поток JPEG-данных.
Внешняя сегментация ускоряет доступ к данным изображения, облегчает его
шифрование и улучшает совместимость с некоторыми JPEG-декодерами.
Комбинированная сегментация
позволяет хранить и воспроизводить версии изображений с несколькими уровнями
разрешения в виде мозаики. Комбинированная сегментация допускает наличие
перекрывающихся сегментов разных размеров, с разными коэффициентами
масштабирования и параметрами сжатия. Каждый сегмент кодируется отдельно и
может комбинироваться с другими сегментами без повторной дискретизации.
Например, в случае использования сегментов размером
8х8 пикселов, для каждого блока формируется набор
чисел. Первые несколько чисел представляют цвет блока в целом, в то время, как последующие числа отражают более тонкие детали. Спектр
деталей базируется на зрительном восприятии человека, поэтому крупные детали
более заметны.
На следующем этапе, в зависимости от выбранного уровня
качества, отбрасывается определенная часть чисел, представляющих тонкие детали.
Таким образом, чем выше уровень компрессии, тем больше
данных отбрасывается и тем ниже качество изображения. Используя JPEG можно
получить файл в 1-500 раз меньше, чем ВМР. Формат аппаратно независим,
полностью поддерживается на РС и Macintosh.
3.2 Дискретное косинусное
преобразование
Ключевым компонентом работы алгоритма является
дискретное косинусное преобразование. Дискретное косинусное преобразование
представляет собой разновидность преобразования Фурье и, так же как и оно,
имеет обратное преобразование. Графическое изображение можно рассматривать как
совокупность пространственных волн, причем оси X и Y совпадают с шириной и
высотой картинки, а по оси Z откладывается значение цвета соответствующего
пикселя изображения. Дискретное косинусное преобразование позволяет переходить
от пространственного представления картинки к ее спектральному представлению и
обратно. Воздействуя на спектральное представление картинки, состоящее из
“гармоник”, то есть, отбрасывая наименее значимые из них, можно балансировать
между качеством воспроизведения и степенью сжатия.
Формулы прямого и обратного дискретного косинусного
преобразования представлены ниже. Дискретное косинусное преобразование
преобразует матрицу пикселов размером NxN в матрицу частотных коэффициентов соответствующего
размера. Несмотря на видимую сложность, закодировать эти формулы достаточно
просто.
Формула дискретного косинусного преобразования.
ДКП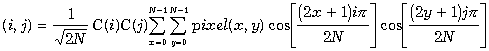
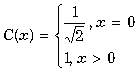
Формула
обратного дискретного косинусного преобразования.
ДКП![]() ДКП
ДКП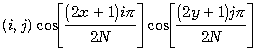
В получившейся матрице коэффициентов низкочастотные
компоненты расположены ближе к левому верхнему углу, а высокочастотные - справа
и внизу. Это важно потому, что большинство графических образов на экране
компьютера состоит из низкочастотной информации. Высокочастотные компоненты не
так важны для передачи изображения. Таким образом, дискретное косинусное
преобразование позволяет определить, какую часть информации можно безболезненно
выбросить, не внося серьезных искажений в картинку.
Реализация
дискретного косинусного преобразования. Время, необходимое для вычисления каждого элемента матрицы
дискретного косинусного преобразования, сильно зависит от ее размера. Так как
используются два вложенных цикла, время вычислений составляет
О (NxN). Одной из особенностей является то,
что практически невозможно выполнить дискретное косинусное преобразование для
всего изображения сразу. В качестве решения этой проблемы группа разработчиков
JPEG предложила разбивать изображение на блоки размером 8x8 точек.
Увеличивая размеры
блока дискретного косинусного преобразования, можно добиться некоторого
увеличения результатов сжатия. Ограничения в коэффициенте сжатия
объясняются малой вероятностью того, что удаленные на значительное расстояние
точки изображения имеют одинаковые атрибуты.
По определению дискретного косинусного преобразования
для его реализации требуется два вложенных цикла, и тело циклов будет
выполняться NxN раз для каждого элемента матрицы
дискретного косинусного преобразования. Значительно более эффективный вариант
вычисления коэффициентов дискретного косинусного преобразования реализован
через перемножение матриц.
При таком подходе формула дискретного косинусного
преобразования может быть записана в следующем виде:
ДКП = КП * Точки * КПт
Где:
- ДКП - дискретное косинусное преобразование;
- КП - матрица косинусного
преобразования размером NxN, элементы которой
определяются по формуле
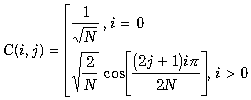
Точки -
матрица размером NxN, состоящая из пикселов изображения;
Кпт - транспонированная матрица КП.
При перемножении матриц “цена” вычисления одного элемента результирующей матрицы составляют N умножений и N сложений, при вычислении матрицы дискретного косинусного преобразования - 2xN соответственно. По сравнению с O(NxN) это заметное повышение производительности. Так как дискретное косинусное преобразование является разновидностью преобразования Фурье, то все методы ускорения преобразования Фурье могут быть применены и в данном случае.
Дискретное косинусное преобразование представляет собой
преобразование информации без потерь и не осуществляет никакого сжатия.
Напротив, дискретное косинусное преобразование подготавливает информацию для
этапа сжатия с потерями или округления.
Округление представляет собой процесс уменьшения
количества битов, необходимых для хранения коэффициентов матрицы дискретного
косинусного преобразования за счет потери точности.
Стандарт JPEG реализует эту процедуру через матрицу
округления. Для каждого элемента матрицы дискретного косинусного преобразования
существует соответствующий элемент матрицы округления. Результирующая матрица
получается делением каждого элемента матрицы дискретного косинусного
преобразования на соответствующий элемент матрицы округления и последующим
округлением результата до ближайшего целого числа. Как правило, значения
элементов матрицы округления растут по направлению слева направо и сверху вниз.
От выбора матрицы округления зависит баланс между
степенью сжатия изображения и его качеством после восстановления. Стандарт JPEG
позволяет использовать любую матрицу округления, однако ISO разработала набор
матриц округления.
Матрица округления
строится при помощи очень простого алгоритма. Для того чтобы определить шаг
роста значений в матрице округления, задается одно значение в диапазоне [1,
25], называемое фактором качества. Затем матрица заполняется следующим образом:
for (i = 0; i < N; i++)
for (j = 0; j < N; j++)
Matrix[i][j] = 1 + (1
+ i + j) * QualityFactor;
Фактор качества задает интервал между соседними
уровнями матрицы округления, расположенными на ее диагоналях. Пример,
полученной таким образом матрицы округления, представлен на рис. 2
|
3 |
5 |
7 |
9 |
11 |
13 |
15 |
17 |
|
5 |
7 |
11 |
13 |
15 |
17 |
19 |
21 |
|
7 |
11 |
13 |
15 |
17 |
19 |
21 |
23 |
|
9 |
11 |
13 |
15 |
17 |
19 |
21 |
23 |
|
11 |
13 |
15 |
17 |
19 |
21 |
23 |
25 |
|
13 |
15 |
17 |
19 |
21 |
23 |
25 |
27 |
|
15 |
17 |
19 |
21 |
23 |
25 |
27 |
29 |
|
17 |
19 |
21 |
23 |
25 |
27 |
29 |
31 |
Рис. 2. Матрица округления с фактором качества, равным 2.
Необходимо отметить, что при таких значениях матрицы
округления коэффициент в матрице дискретного косинусного преобразования,
расположенный в ячейке (7,7), должен принимать значение не меньше 16, чтобы
после округления иметь значение, отличное от 0, и влиять на декодируемое
изображение. Таким образом, операция округления является единственной фазой
работы JPEG, где происходит потеря информации.
Вычисления при использовании метода DCT чрезвычайно
сложны; фактически — это наиболее трудоемкий этап сжатия JPEG. Выполнив его, мы
практически разделяем высокочастотную и низкочастотную информацию, из которых состоит изображение. После этого можно отбросить
высокочастотные данные без потери низкочастотных. Сам
по себе этап преобразования DCT не предусматривает потерь, за исключением
ошибок округления.
Прежде чем отбросить определенный объем информации,
компрессор делит каждое выходное значение DCT на "коэффициент
квантования", округляя результат до целого. Чем больше коэффициент
квантования, тем больше данных теряется, поскольку реальное DCT-значение
представляется все менее и менее точно. Каждая из 64 позиций выходного блока
DCT имеет собственный коэффициент квантования. Причем термы большего порядка
квантуются с большим коэффициентом, чем термы меньшего порядка. Кроме того, для
данных яркости и цветности применяются отдельные таблицы квантования,
позволяющие квантовать данные цветности с большими коэффициентами, чем данные
яркости. Таким образом, JPEG использует различную чувствительность глаза к
яркости и цветности изображения.
На этом этапе большинство JPEG-компрессоров
управляются с помощью установки качества. Компрессор использует встроенную
таблицу, рассчитанную на среднее качество, и наращивает или уменьшает значение
каждого элемента таблицы обратно пропорционально требуемому качеству.
Применяемые таблицы квантования записываются в сжатый файл, чтобы декомпрессор
знал, как восстановить коэффициенты DCT (приблизительно).
Выбор соответствующей таблицы квантования является
"высоким искусством". Большинство существующих компрессоров
используют таблицу, разработанную Комитетом JPEG ISO. Возможно, со временем
будут предложены таблицы, позволяющие осуществлять сжатие более эффективно и
при сохранении качества изображения.
3.3 Кодирование. Заключительная стадия работы кодера JPEG
Заключительная стадия работы кодера JPEG - это
собственно кодирование. Оно включает три действия над округленной матрицей
дискретного косинусного преобразования, для того, чтобы повысить степень
сжатия.
Первое действие - это замена абсолютного значения
коэффициента, расположенного в ячейке (0,0) матрицы, на
относительное. Так как соседние блоки изображения в значительной степени
“похожи” друг на друга, то кодирование очередного (0,0) элемента как разницы с
предыдущим дает меньшее значение.
Коэффициенты
матрицы дискретного косинусного преобразования обходятся зигзагом. После чего
нулевые значения кодируются с использованием алгоритма кодирования повторов
(RLE), а потом результат обрабатывается с помощью “кодирования энтропии”, то
есть алгоритмов Хаффмана или арифметического кодирования, в зависимости от
реализации.
“Кодирование
энтропии”. Результатом работы,
упрощенной схемы кодирования, являются тройки следующего вида:
<КоличествоНулей, КоличествоБитов, Коэффициент>
Здесь:
КоличествоНулей - количество повторяющихся нулей, предшествующих
текущему (ненулевому) элементу матрицы дискретного косинусного преобразования;
КоличествоБитов - количество битов, следующих далее, кодирующих
значение коэффициента;
Коэффициент - значение ненулевого элемента матрицы
дискретного косинусного преобразования.
Соответствие между полями КоличествоБитов
и Коэффициент приведено в Таблице 2.
Таблица 8
Количество Битов |
Коэффициент |
|
1 |
[-1, 1] |
|
2 |
[-3, -2], [2, 3] |
|
3 |
[-7, -4], [4, 7] |
|
4 |
[-15, -8], [8, 15] |
|
5 |
[-31, -16], [16, 31] |
|
6 |
[-63, -32], [32, 63] |
|
7 |
[-127, -64], [64, 127] |
|
8 |
[-255, -128], [128, 255] |
|
9 |
[-511, -256], [256, 511] |
|
10 |
[-1023, -512], [512, 1023] |
Такое кодирование не столь эффективно, как кодирование
Хаффмана, но на определенных данных оно дает аналогичные результаты.
После завершения этого этапа поток данных JPEG готов к передаче по коммуникационным каналам или инкапсуляции в формат файла изображения.
Формат JFIF
Строго говоря, JPEG
обозначает рассмотренный выше алгоритм сжатия, а не конкретный формат
представления графической информации. Практически любую графическую информацию
можно сжать по такому алгоритму. Формат файлов, использующих алгоритм JPEG, формально называют JFIF (JPEG File
Interchange Format). На
практике, очень часто файлы, использующие JPEG - сжатие, называют JPEG - файлами.
4.
Основы сжатия видеоизображения: кодирование и декодирование
Сжатие видеоизображения заключается в удалении
избыточных видеоданных или сокращении их объема, благодаря чему файлы с
оцифрованным видео удается эффективно передавать по сети и хранить. При сжатии
к исходному видеоизображению применяется определенный алгоритм. Применение
обратного алгоритма позволяет практически без потерь восстановить оригинальное
видеоизображение. Такая пара алгоритмов называется кодеком (кодировщик/декодировщик).
Результаты работы кодировщиков, построенных на одном и
том же стандарте сжатия, могут различаться. Это связано с тем, что разработчик
программы может по своему выбору реализовать тот или иной набор средств сжатия, предусмотренных стандартом. Это считается
допустимым, поскольку итоговый файл имеет установленный стандартом формат и
может быть декодирован. Поэтому, не разобравшись сначала в деталях той или иной
реализации, невозможно оценить эффективность стандарта по сравнению с другими
стандартами и даже с другими его реализациями.
При реализации декодера,
напротив, обязательно должны быть реализованы все заявленные в стандарте
средства. Это связано с тем, что стандарт четко устанавливает порядок
восстановления каждого бита сжатого видеоизображения.
Основные методы сжатия данных
Для сжатия видеоданных, как в рамках одного кадра, так
и в пределах последовательности, состоящей из нескольких кадров, применяются
различные методы. Сжатие в пределах кадра осуществляется обычно за счет
удаления избыточной информации. При работе с несколькими кадрами могут
применяться такие методы, как дифференциальное кодирование и поблочная
компенсация движения.
При дифференцированном кодировании изображение в кадре
сравнивается с изображением в опорном кадре (предшествующий I- или P-кадр). При этом кодируются только те
пиксели, цвет которых изменился. Следовательно, кодируется и передается меньшее
количество пикселей.
Однако, если сжимаемое
изображение интенсивно меняется, дифференциальное кодирование не позволяет
достичь значительного сжатия. Для таких случаев больше подходит поблочная
компенсация движения. В основу это метода положена идея о том, что большинство
элементов изображения, составляющих очередной кадр, можно найти на предыдущем
кадре, но на других местах. Поэтому кадр разбивается на
несколько макроблоков – блоков пикселей. Блок за блоком
новый кадр (например, P-кадр) сравнивается с опорным кадром. Если найден
совпадающий блок, кодировщик сохраняет только информацию о том, где этот блок
расположен на опорном кадре. Для того, чтобы сохранить
такой вектор перемещения требуется меньше бит, чем на кодирование содержимого
блока.
4.1
Форматы сжатия в видео-регистраторах
Существует два основных
формата сжатия видио:
• Формат M-JPEG
• Формат MPEG-4
Формат
M-JPEG
MJPEG (Motion
JPEG) — покадровый метод видеосжатия,
основной особенностью которого является сжатие каждого отдельного кадра видеопотока с помощью алгоритма сжатия изображений JPEG.
При сжатии методом MJPG межкадровая разница не учитывается.
Преимущества
и недостатки
Основным преимуществом видеосжатия
Motion JPEG является простота реализации, что делает
MJPG подходящим для реализации в устройствах с ограниченными вычислительными
ресурсами.
Чрезвычайно быстрый нелинейный видеомонтаж — если
какой-либо кадр берётся целиком (без изменений) из одного MJPEG-источника, его
можно записать в выходной MJPEG-поток как есть, без декодировки-сжатия.
MJPEG даёт качественные стоп-кадры, что позволяет его
использовать, например, в системах видеонаблюдения
(там это важно - например, чтобы выяснить номер проехавшего автомобиля).
К недостаткам можно отнести более низкий коэффициент
сжатия по сравнению с потоковыми методами сжатия, например MPEG-4.
Использование в видеорегистраторах
Как писалось выше - нетребовательность к
вычислительными ресурсами делает M-JPEG привлекательным для цифровых
видеорегистраторов. На самом деле, в мире M-JPEG не
существует как отдельный стандарт, скорее он относится к быстрому потоку
изображений JPEG, которые могут быть воспроизведены с достаточно высокой
скоростью, создавая при этом иллюзию движения. Поскольку зависимости между отдельными
последовательными кадрами не берутся в расчет, такой способ позволяет получить
только относительно небольшой уровень сжатия по сравнению со стандартами,
использующими сжатие видеоизображения, например такими, как разновидности Н.26х
или MPEG, которые описаны на сайте отдельно.
M-JPEG никогда не был предметом международной
стандартизации, a JPEG не определяет стандарт
передачи, поэтому способы реализации M-JPEG у разных поставщиков регистраторов
несовместимы между собой. Для увеличения степени сжатия некоторые производители
видеорегистраторов умудряются использовать и сжатие
разницы между двумя соседними кадрами. Однако, этот
вариант тоже не является стандартным, поэтому для воспроизведения таких данных
потребуется программное обеспечение того же поставщика видеорегистратора.
Цифровые видеорегистраторы,
работающие с MPEG-4 становятся все более популярными в системах видеонаблюдения.
4.2 Формат MPEG-4
MPEG-4 - это международный стандарт, используемый
преимущественно для сжатия цифрового аудио и видео. Он появился в 1998 году, и
включает в себя группу стандартов сжатия аудио и видео
и смежные технологии, одобренные ISO — Международной Организацией по
стандартизации/IEC Moving Picture
Experts Group (MPEG).
Стандарт MPEG-4 в основном используется для вещания (потоковое видео), записи
дисков с фильмами на компакт-диски, видеотелефонии
(видеотелефон), и широковещания, в которых активно используется сжатие цифровых
видео и звука.
Формат MPEG-4 предоставляет конечным пользователям
широкий спектр возможностей, позволяющих взаимодействовать с различными
анимированными объектами.
·
Мультиплексирование
и синхронизация данных, связанных с медийным
объектом, в том смысле, что они могут быть переданы через сетевые каналы.
·
Аудио потоки, видео и аудиовизуальные данные могут быть как естественными,
так и искусственно созданными. Это означает, что они могут быть
как записаны на видеорегистратор или микрофон, так и
созданы с помощью компьютера и специального программного обеспечения.
·
MPEG-4
обеспечивает технологии, позволяющие осуществлять доступ не к пикселам, а к объектам, просматривать их и манипулировать
ими.
·
MPEG-4 отличается
большой устойчивостью к ошибкам и работой с несколькими диапазонами значений
скорости передачи данных.
·
Сфера применения
стандарта варьируется в широком диапазоне от цифрового телевидения, мультимедийных данных в мобильных коммуникациях, игр и до видеонаблюдения.
Главное отличие MPEG-4 от
предыдущих стандартов заключается в его объектно-ориентированной
аудиовизуальной модели. В рамках этой модели в каждой сцене присутствуют
объекты, которые имеют связи между собой во времени и пространстве, что дает
ряд преимуществ. Стандарт MPEG-4 открывает пользователям новые возможности для
создания, редактирования, доступа и потребления аудиовизуальной
информации. В основе технологии MPEG-4 лежит объектно-ориентированный подход,
где сцена моделируется как состоящая из объектов, как естественных, так и
синтезированных, с которыми пользователь может взаимодействовать. Работа с
объектами (особенно с синтезированными)
и интерактивность лежат в основе MPEG-4, но, к сожалению, в системах видеонаблюдении это не нашло применения.
Стандарт MPEG-4 был оптимизирован для передачи данных
в трех диапазонах скоростей: менее 64 кбит/с, 64 — 384 кбит/с и 384 кбит/с — 4
Мбит/с.
MPEG-4 предлагает набор
инструментов и технологий, которые пригодны для различных областей приме- нения как в существующих приложениях, так и в тех,
которые появятся в будущем. Низкие скорости пере- дачи
данных и устойчивость к ошибкам позволяют использовать MPEG-4 для надежной
передачи по низкоскоростным радиоканалам, что удобно для мобильных видеофонов,
коммуникаций в космосе и, конечно, в видеонаблюдении.
MPEG-4 разрабатывался не как монолитный стандарт, а
скорее как набор инструментов, которые вместе с профилями обеспечивают решение
конкретных задач. Хотя MPEG-4 представляет собой достаточно обширный стандарт,
он имеет такую структуру, которая позволяет получать доступ к разным
инструментам по мере необходимости. Каждый разработчик может выбрать из обширного
стандарта MPEG-4 только тот инструментарий, который ему требуется, что с
большой долей вероятности будет представлять очень незначительную часть
стандарта.
Цифровые видеорегистраторы,
работающие с MPEG-4 становятся все более популярными в системах видеонаблюдения, хотя они и используют разные профили
MPEG-4 и, таким образом, отличаются по качеству изображения между собой.
MPEG-4 не заменяет, как считают
некоторые, стандарт MPEG-2, но предлагает большую гибкость в работе на
низкоскоростных каналах связи и позволяет передавать практически «живое» видео
при скорости передачи 256 кбит/с. Некоторые производители включают MPEG-4 в
свои цифровые видеорегистраторы для удаленного
просмотра и управления, тогда как для локальной записи используются другие
алгоритмы сжатия.
5.
Интересные факты
В 2010 году ученые из
проекта PLANETS поместили инструкции по чтению формата JPEG в специальную
капсулу, которую поместили в специальный бункер в швейцарских Альпах. Сделано
это было с целью сохранения для потомков информации о популярных в начале XXI
века цифровых форматах.
Заключение
На основе JPEG - метода сжатия построены
многочисленные форматы, например, формат TIFF/JPEG, известный как TIFF 6.0,
TIFF, QuickTime и др.
Файлы с графикой в формате JPEG имеют расширение *.jpg.
Формат JPEG является TrueColor-форматом, то есть может
хранить изображения с глубиной цвета 24 бит/пиксел.
Такой глубины цвета достаточно для практически точного воспроизведения
изображений любой сложности на экране монитора. В случае просмотра цветного изображения
на экране монитора большая глубина цвета (например, 32 бит/пиксел)
практически не отличается от изображения с глубиной цвета в 24 бит/пиксел. Тот же результат наблюдается и при распечатке
изображения на большинстве доступных принтеров. Глубина цвета в 32 бит/пиксел, как правило, используется в издательской
деятельности.
JPEG обладает более высокой степенью сжатия
изображений, нежели GIF, но не обладает возможностью хранить несколько
изображений в одном файле. Правда, известна модификация формата JPEG,
получившая название Progressive JPEG, который
предназначен для тех же задач, что и чересстрочное отображение GIF-изображений.
Это сделало формат JPEG более привлекательным в качестве сетевого стандарта.
JPEG ориентирован, прежде всего, на реалистичные
изображения, то есть изображения фотографической направленности, и качество
сжатия значительно ухудшается при обработке изображений с четко очерченными
линиями и границами цветов.
Алгоритм JPEG и построенные на его основе форматы
предусматривают реализацию функциональной возможности, получившей название этикетка.
Фактически это уменьшенная копия изображения. Этикетку можно рассматривать
как своего рода аналог предложенного в формате GIF приема черезстрочной
развертки изображения. То есть, при наличии большого количества файлов JPEG
можно выводить их на экран в виде этикеток, что позволяет отобразить их
достаточно быстро или в большое количество (списком) и, тем самым, дать
пользователю представление о содержимом каждого файла. Этикетки могут быть
закодированы методом JPEG; сохранены в формате 1 байт/пиксел
(т.е. в виде полутонового изображения) или представлены в виде полноцветного изображения с 16,7 млн.цветов(24
бит/пиксел).
JPEG может рассматриваться как набор методов сжатия
изображений, пригодных для удовлетворения нужд пользователя. JPEG может
настраиваться на воспроизведение очень маленьких, сжатых изображений
относительно плохого качества, но подходящих для требуемых целей. В то же
время, он позволяет производить сжатие изображений очень высокого качества,
объем данных которых намного меньше, чем у
оригинальных несжатых данных.
JPEG, как правило, сопровождается потерями. Схемы
сжатия JPEG основана на отбрасывании информации,
которую трудно заметить визуально. Известно, что небольшие изменения цвета плохо
распознаются глазом человека.
Схема JPEG была специально разработана для сжатия
цветных и полутоновых многоградационных изображений
фотографий, телевизионных заставок, другой сложной графики. Конечный
пользователь может "отрегулировать" качество кодировщика JPEG, использовав параметр, который иногда называют установкой
качества или Q-фактором. Различные реализации данного метода имеют разные
диапазоны Q-фактора, но типичным считается 1 до 100. При значении фактора,
равном 1, создается сжатое изображение самого маленького размера, но плохого
качества; при значении фактора, равном 100, можно получить сжатое изображение
большего размера, но и лучшего качества. Оптимальное значение Q-фактора зависит
от содержимого изображения и, следовательно, подбирается индивидуально. Особым
искусством при сжатии JPEG является выбор минимального значения Q-фактора,
позволяющего создать изображение приемлемого качества и наиболее близкое к
оригиналу.
Наряду с вышесказанным необходимо отметить, что
графическая анимация, черно-белые иллюстрации, документы, а также типичная
векторная графика, как правило, JPEG сжимаются плохо.
В настоящее время JPEG стали использовать для
сжатия видеоинформации, однако авторам не известны полученные
результаты.
Формат JPEG получил большое распространение в Web
– публикациях для представления графических элементов Web – страницы, в тех
случаях, когда требуется многоцветное качественное изображение.
Список литературы
1. Д.С. Ватолин.
“Сжатие статических изображений” Открытые системы сегодня. Номер 8 (29) Апрель
1995
2. Д.С. Ватолин.
“Тенденции развития алгоритмов архивации графики” Открытые системы. Номер 4.
Зима 1995
3. А.С. Климов “Форматы
графических файлов”,НИПФ “ДиаСофт
Лтд”, 1995
4. http://ru.wikipedia.org/wiki/JPEG
5. http://www.0x99.ru/?topic_id=43
6. http://www.armosystems.ru/system/cctv_compression_jpeg.ahtm
7. http://sigadoma.ru/videonablyudenie/formaty-zapisi-videoregistratorov.html
8. http://factopedia.ru/fact/2418
9. http://www.ereading.co.uk/chapter.php/1006730/125/Osnovy_raboty_v_Adobe_Photoshop_CS5.html
10. http://web-design-courses.narod.ru/graphics.html